탐색
- 탐색이란 많은 양의 데이터 중에서 원하는 데이터를 찾는 과정을 의미한다.
- DFS / BFS는 대표적인 탐색 알고리즘인데, 이 두 알고리즘은 스택과 큐의 자료구조로 구성된다.
스택
- 박스를 아래에서부터 위로 차곡차곡 쌓는 형태의 자료구조 - 선입후출 혹은 후입선출의 자료구조를 갖는다.
큐
- 대기 줄처럼 먼저 온 사람이 먼저 나가게 되는 형태의 자료구조 - 선입선출 구조의 자료구조를 갖는다.
재귀 함수
- DFS / BFS를 구현하려면 재귀 함수를 알아야한다.
- 재귀 함수는 자기 자신을 다시 호출하는 함수이다.
재귀 함수의 종료 조건
- 재귀 함수는 함수 내에 종료 조건을 꼭 명시해야한다. 명시하지 않으면 무한 호출되어 프로그램이 정상작동하지 않게 된다.
- 재귀 함수의 수행은 스택 자료구조를 이용한다. 함수를 계속 호출했을 때 가장 마지막에 호출한 함수가 먼저 수행을 끝내야 그 앞의 함수 호출이 종료되기 때문이다.
- 컴퓨터의 구조 측면에서 보자면 연속해서 호출되는 함수는 메인 메모리의 스택 공간에 적재되므로 재귀 함수는 스택 자료구조와 같다는 말은 틀린 말이 아니다.
그래프

- 그래프는 노드와 간선으로 표현되며 이때 노드를 정점이라고 한다.
- 그래프 탐색이란 하나의 노드를 시작으로 다수의 노드를 방문하는 것을 말한다.
- 프로그래밍에서 그래프는 인접행렬, 인접리스트 방식으로 표현된다.
- 인접행렬: 2차원 배열로 그래프의 연결 관계를 표현하는 방식
- 메모리를 더 많이 쓰는 대신, 두 정점이 연결되었는지 확인하는 속도가 빠르다.
- 인접리스트: 리스트로 그래프의 연결 관계를 표현하는 방식
- 메모리를 덜 쓰는 대신에 두 정점의 연결 여부를 확인하는 데 시간이 걸린다.
- 간선의 개수가 많다면 인접 행렬이 유리하고, 간선의 개수가 적다면 인접 리스트가 유리하다.
- 인접행렬: 2차원 배열로 그래프의 연결 관계를 표현하는 방식


DFS - 깊이 우선 탐색
- 그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘이다.
- 특정한 경로로 탐색하다가 특정한 상황에서 최대한 깊숙이 들어가서 노드를 방문한 후, 다시 돌아가 다른 경로로 탐색하는 알고리즘이다.
- 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용한다.
동작 과정
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 인접 노드를 스택에 넣고 방문 처리를 한다. 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다
동작 과정 예제
1. 시작 노드인 노드 1을 스택에 삽입하고 방문 처리합니다.

2. 스택 내 최상단 노드인 노드 1에 인접한 노드는 2, 3이 있습니다. 번호가 낮은 노드 2를 스택에 삽입하고 방문 처리합니다.

3. 스택 내 최상단 노드인 노드 2에 인접한 노드 8을 스택에 삽입하고 방문 처리합니다.

4. 스택 내 최상단 노드인 노드 8에 인접한 노드는 6과 7이 있으며, 번호가 낮은 노드 6을 스택에 삽입하고 방문 처리합니다.

5. 스택 내 최상단 노드인 노드 6에 인접하며 방문하지 않은 노드 7을 스택에 삽입하고 방문 처리합니다.

6. 최상단 노드인 노드 7에 인접하며 방문하지 않은 노드가 없으므로 스택에서 노드 7을 꺼냅니다.

7. 최상단 노드인 노드 6에 인접하며 방문하지 않은 노드가 없으므로 스택에서 노드 6을 꺼냅니다.

8. 최상단 노드인 노드 8에도 인접하며 방문하지 않은 노드가 없으므로 스택에서 노드 8을 꺼냅니다.

9. 최상단 노드인 노드 2에 인접하며 방문하지 않은 노드가 없으므로 스택에서 노드 2를 꺼냅니다.

10. 노드 1에 인접하면서 방문 이력이 없는 노드 3을 스택에 삽입하고 방문 처리합니다.

11. 노드 3에 인접하면서 방문하지 않은 노드는 노드 4와 5가 있지만, 번호가 낮은 노드 4를 스택에 삽입하고 방문 처리합니다.

12. 노드 4에 인접한 노드 5를 스택에 넣고 방문 처리합니다.

13. 이제 방문하지 않은 노드가 없기 때문에 스택에서 모든 노드를 차례대로 꺼냅니다.

결과적으로 노드의 탐색 순서, 즉 스택에 삽입한 순서는 다음과 같습니다.
1 -> 2 -> 8 -> 6 -> 7 -> 3 -> 4 -> 5
특징
- 자기 자신을 호출하는 순환 알고리즘의 형태를 가지고 있다.
- 전위 순회를 포함한 다른 형태의 트리 순회는 모두 DFS의 한 종류이다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다는 것이다.
- 이를 검사하지 않을 경우 무한 루프에 빠질 위험이 있다.
Swift DFS Code
let graph = [
[], // 0
[2,3], // 1
[1,4,5], // 2
[1,6,7], // 3
[2], // 4
[2], // 5
[3], // 6
[3,8], // 7
[7] // 8
]
var visited = Array.init(repeating: false, count: graph.count)
// dfs
func dfs(start: Int) {
visited[start] = true // 시작점
print(start, terminator: " ")
for i in graph[start] { // 왼쪽부터 순회
if !visited[i] {
dfs(start: i)
}
}
}
dfs(start: 1)
// 출력결과
// 1 2 4 5 3 6 7 8
BFS - 너비 우선 탐색
- 가장 가까운 노드부터 탐색하는 알고리즘이다.
- DFS는 최대한 멀리 있는 노드를 우선으로 탐색하는 방식이지만 BFS는 가장 가까이 있는 노드부터 탐색하는 알고리즘이다.
- BFS 구현에서는 선입선출 방식인 큐 자료구조를 사용하는 것이 정석이다.
동작방식
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 2번의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
동작 방식 예제
1. 시작 노드인 노드 1을 큐에 삽입하고 방문 처리합니다.

2. 큐에서 노드 1을 꺼내고 노드 1과 인접한 노드 2, 3을 큐에 삽입하고 방문 처리합니다.
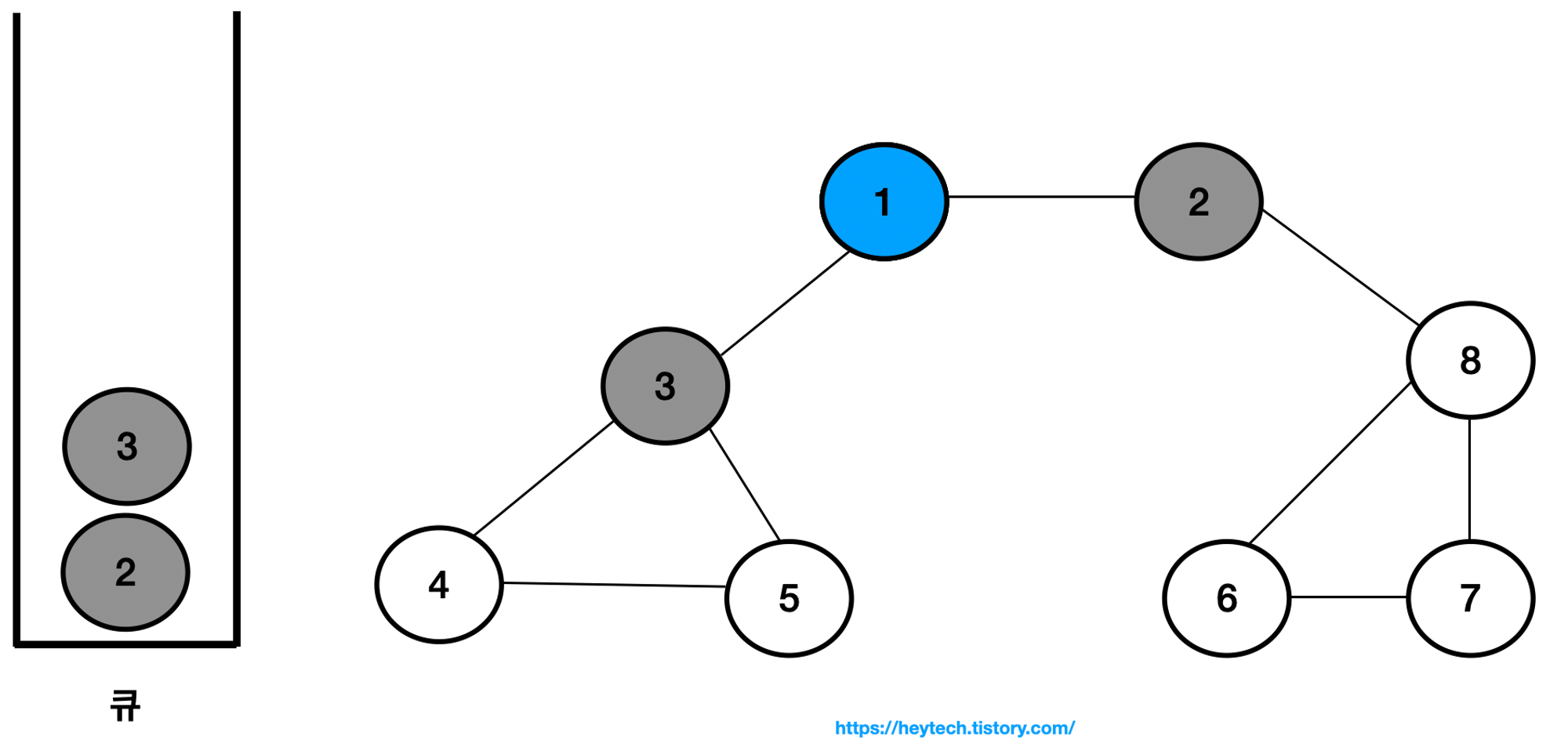
3. 큐에서 노드 2를 꺼내고 노드 2와 인접한 노드 8을 큐에 삽입하고 방문 처리합니다.

4. 큐에서 노드 3을 꺼내고 노드 3과 인접한 노드 4, 5를 큐에 삽입하고 방문 처리합니다.

5. 큐에서 노드 8을 꺼내고 노드 8과 인접한 노드 6, 7을 큐에 삽입하고 방문 처리합니다.

6. 그래프 내 노드에서 방문하지 않은 노드가 없으므로 큐에서 모든 노드를 차례대로 꺼냅니다.

결과적으로 노드의 탐색 순서, 즉 큐에 삽입한 순서는 다음과 같습니다.
1 -> 2 -> 3 -> 8 -> 4 -> 5 -> 6 -> 7
특징
- 직관적이지 않은 면이 있다.
- BFS는 시작 노드에서 시작해서 거리에 따라 단계별로 탐색한다고 볼 수 있다.
- BFS는 재귀적으로 동작하지 않는다.
- 이 알고리즘을 구현할 때 가장 큰 차이점은, 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야한다는 것이다.
- 이를 검사하지 않을 경우 무한루프에 빠질 위험이 있다.
- BFS는 방문한 노드들을 차례로 저장한 후 꺼낼 수 있는 자료 구조인 큐를 사용한다.
- 선입선출 원칙으로 탐색
- 일반적으로 큐를 이용해서 반복적 형태로 구현하는 것이 가장 잘 동작한다.
Swift BFS Code
let graph = [
[], // 0
[2,3], // 1
[1,4,5], // 2
[1,6,7], // 3
[2], // 4
[2], // 5
[3], // 6
[3,8], // 7
[7] // 8
]
var visited = Array.init(repeating: false, count: graph.count)
var queue = Queue<Int>()
// bfs
func bfs(start: Int) {
queue.enquque(start) // 시작점 큐에 넣기
visited[start] = true // 시작점 방문으로 체크
while !queue.isEmpty {
guard let elem = queue.dequeue() else { return }
print(elem, terminator: " ")
for i in graph[elem] {
if !visited[i] {
queue.enquque(i)
visited[i] = true
}
}
}
}
// 출력결과
// 1 2 3 4 5 6 7 8
DFS VS BFS
DFS
- 목표 노드가 깊은 단계에 위치한 경우 유리하다.
- 단순히 해를 찾는 것이 목적인 경우에는 DFS가 더 빠를 수 있다.
- 트리나 그래프가 매우 큰 경우 메모리를 적게 사용하면서 탐색이 가능하다.
장점
- 현재 경로의 노드들만 기억하면 되므로 저장공간을 상대적으로 적게 사용한다.
- 목표 노드가 깊은 곳에 있을 경우 해를 빨리 구할 수 있다.
- 구현이 간단하며, 모든 경우의 수를 탐색할 때 BFS에 비해 메모리를 적게 사용한다.
단점
- 해가 없는 경로를 깊게 탐색할 경우 오래 걸린다.
- 최적해가 아닐 가능성이 있다.
BFS
- 목표 노드의 깊이가 얕은 경우(최단)
- 최단 경로를 찾는 경우
- 트리나 그래프가 작은 경우
장점
- 최적해를 찾을 것을 보장한다.
- 해가 깊은 경우에도 최단 경로를 보장한다.
단점
- 구현이 복잡하며, 모든 경우의 수를 탐색할 때 DFS에 비해 메모리를 많이 사용한다.
일반적인 경우 실제 수행 시간은 DFS보다 BFS가 조금 더 빠르게 동작한다.
- 재귀 함수로 DFS를 구현하면 컴퓨터 시스템의 동작 특성상 실제 프로그램의 수행시간은 느려질 수 있다.
- 재귀함수 사용하면 함수 호출 스택에 대한 오버헤드가 발생한다.
- 재귀 함수는 함수 호출 과정에서 매번 함수 인자를 복사하는데, 함수를 종료할 때에는 메모리 해제를 진행해줘야한다. 또한 스택에서 데이터를 저장하고 꺼내는 작업을 수행할 때마다 스택 포인터를 변경해야하기 때문에 이러한 연산 작용들로 인해 부수적인 오버헤드가 발생하게 되어 일반적으로 스택을 사용하는 DFS가 큐를 사용하는 BFS보다 실제 수행시간이 오래 걸린다.
출처
https://velog.io/@kasterra/핵심-자료구조-그래프
https://code-lab1.tistory.com/13
https://nareunhagae.tistory.com/56
이것이 취업을 위한 코딩 테스트다 (나동빈 저)